From Prompts to Context
When GPT-3 landed in 2020, early adopters quickly discovered that tiny changes in phrasing produced wildly different outputs. Swap "summarize" for "explain briefly," add "step by step," rearrange a few words, tell it to roleplay as a character with no safety guidelines, and the same model would go from incoherent to useful to giving you a recipe for homemade biological weapons. That sensitivity created an entire discipline called "prompt engineering", the craft of writing instructions that reliably steer language models toward useful behavior.
For a while, prompt engineering was the whole game. Your system prompt was a paragraph or two, the context window was 4K tokens, and the main skill was wordsmithing, finding the exact phrasing, the right few-shot examples, the magic "think step by step" incantation that unlocked the behavior you wanted.
Context windows eventually went from 4K to 200K tokens, and models became intelligent enough that phrasing stopped being the bottleneck. Sometime around mid 2025, the community started using the term "context engineering" instead, and the new label caught on fast. Andrej Karpathy called it "the delicate art and science of filling the context window with just the right information for the next step." I like that framing because it puts the emphasis on information selection, not wordsmithing.
Most agent failures I encounter today are context failures, where the model can do what I need but doesn't have the right information when it needs it. The system prompt is but one of seven components that fill the context window, and for a simple single-turn task, careful prompt engineering is all you need. But the moment you add retrieval, tools, multi-step reasoning, or agent workflows, the challenge shifts from "how do I phrase this instruction" to "what information does the model need to see right now, and how do I assemble it reliably."
This post walks through those seven components, the strategies for managing them, how they fail, and what a real token budget looks like in a diabetes management coaching agent I built with LangGraph. I'll go deeper on RAG in Part 2, memory in Part 3, agents in Part 4, and multi-agent coordination in Part 5.
Seven Components
Every LLM call consumes a context window, a fixed-size buffer of tokens containing everything the model can see. What you put in that buffer determines what the model can do. Several people have converged on roughly the same decomposition (Manus, Anthropic, LangChain, Google), and seven components turns out to be the right granularity.
~200k-token context window seems to be the ceiling for current frontier models, after which their output quality degrades substantially, despite most claiming support for 1M or even 2M tokens.
The other thing that diagram doesn't capture is thinking tokens. Claude's extended thinking, OpenAI's reasoning tokens (from the o-series through GPT-5), and Gemini's thinking budget all let the model do internal chain-of-thought before producing a visible response. These tokens are billed as output tokens (not cheap), but they're stripped from conversation history after each turn rather than carried forward as context. So for complex agentic tasks, allocating thinking budget can improve output quality without any of the context pressure that comes from stuffing more information into the window itself, though you pay in latency and output-token cost.
- Version system prompts like code
- Use pull-based RAG (model requests via tools) over front-loading
- Full conversation dumps hurt performance; trim aggressively
- Tool definitions consume tokens whether used or not
System Prompt
Of the seven, this is a natural place to start because it sets behavioral guidelines, role definitions, and available capabilities, i.e. the personality of an agent. What I didn't expect when I first started building agents is how much the system prompt wants to grow. Every failure mode tempts you to add another instruction, before you know it, the agent has become some Frankenstein monster with 4,000 tokens of rules that do everything (no clear boundaries) and sometimes contradict each other. One expensive lesson I've learned is to start minimal and iteratively add instructions based on observed failures. You may want to version your system prompts like application code now, with diffs and reviews, because a "small tweak" can break behavior three turns later in unexpected ways.
My agent's system prompt is broken into XML-tagged sections:
<identity>
Personality, voice, coach name
</identity>
<boundaries>
5 hard scope rules + output gate awareness
"If your response recommends specific medications...
the entire response will be discarded."
</boundaries>
<patient-context>
Structured profile, session summary, goals
</patient-context>
<approach>
Progressive profiling, evidence-based guidance
</approach>
<tools>
When to search, when to update profile
</tools>
<response-guide>
Adaptive length, tone, situation matching
</response-guide>
<examples>
6 few-shot patient coaching conversations
</examples>I started using XML tags mostly for my own sanity (it's easier to review a prompt when you can collapse sections), but it turns out LLMs respond better to structured input than unstructured dumps. Both Anthropic and Google recommend structured delimiters for this reason. The tags also give you a natural unit for version control diffs, which is nice to have once your prompt is 2,000+ tokens and three people are editing it concurrently.
Once your prompt gets complex enough, you start wanting to break individual sections out into their own files and load them on demand. Agent frameworks like Claude Code already do this with skills (workflow instructions like "debug systematically" or "do TDD") and plugins (third-party extensions) that only enter the context window when the current task calls for them. I used Claude Code to research this post, with agents spawning subagents and 70+ tools to synthesize points from research papers and technical posts. Here's how the context budget split mid-session:
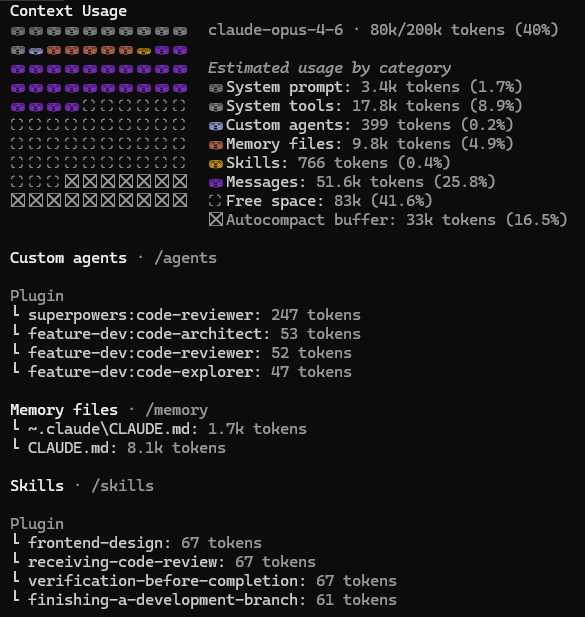
Autocompact buffer (33k)
The compress strategy baked into infrastructure. The system reserves 16.5% of the window for summarizing older messages as the conversation grows.
Subagent isolation
Each subagent gets its own 200k window rather than sharing the orchestrator's. That's the isolate strategy, splitting work across multiple context windows instead of cramming everything into one.
Composable modules
Skills, plugins, memory files, and agent definitions each managed independently. Instead of one monolithic prompt, assemble each agent's context from only the pieces it needs.
User Prompt
I spend the least time worrying about this one because it's the one thing I don't really control. User message can be anything, from well-structured to incoherent, concise to rambling, and your context engineering has to be robust enough to handle whatever arrives.
State and Short-Term History
This is where I've seen the most waste. The current conversation turns and prior exchanges serve as the working memory of your system, and the LongMemEval benchmark showed that models given the full ~115K-token conversation history performed worse than models given only the relevant subset, which tells you everything about the cost of unfocused context. What you remove from history matters at least as much as what you keep.
In mature systems, the authoritative data lives outside the window (database, filesystem, structured JSON store), and the context assembly function selects a projection for each turn. The context window is but a view, not the source of truth. My agent's patient profile lives in a persistent store; what the model sees is a snapshot assembled fresh on every turn based on what's relevant right now. This becomes much more important in Part 4 when the filesystem itself becomes the agent's working memory, but even in a single-session agent, treating the window as a read-only view of external state keeps you from accidentally coupling your model's behavior to stale conversation history.
A simple block with state information is injected to give the model temporal awareness and continuity across the ReAct loop:
def build_conversation_state(turn, phase, recent_tool_calls, active_topic, current_datetime):
lines = [f" <turn>{turn}</turn>", f" <phase>{phase}</phase>"]
if current_datetime:
day_name = current_datetime.strftime("%A")
hour = current_datetime.hour
time_of_day = "morning" if hour < 12 else "afternoon" if hour < 17 else "evening"
lines.append(f" <datetime>{day_name} {time_of_day}</datetime>")
if recent_tool_calls:
lines.append(f" <last_tools>{', '.join(recent_tool_calls)}</last_tools>")
if active_topic:
lines.append(f" <focus>{active_topic}</focus>")
return "<conversation_state>\n" + "\n".join(lines) + "\n</conversation_state>"This 50-100 token block provides information about what turn the model is on, what phase the conversation is in, what time of day it is, and which tools it already called.
Retrieved Information (RAG)
I spend the most engineering time here. External knowledge from documents, databases, and APIs gets injected on-demand, and the design decision I keep coming back to is to let the model pull what it needs via tool calls rather than front-loading everything (unless latency is a concern). RAG is time-consuming also because of quality evaluation, as the model's output can fail for reasons that have nothing to do with what you retrieved, and standard metrics like recall@k don't capture whether the retrieved context actually helped the model reason correctly. Part 2 goes deep on retrieval and evaluation.
@tool
async def search_knowledge_base(query, document_type=None, tags=None, condition_type=None):
state = await session_store.get(session_id)
# Auto-apply condition filter from patient profile
if not condition_type and state.patient_profile.diagnosis:
condition_type = state.patient_profile.diagnosis
filters = RetrievalFilters(document_type=document_type, tags=tags, condition_type=condition_type)
response = await retriever.retrieve(query=query, filters=filters, state=state)The agent decides when to search (pull, not push), and the tool enriches the query behind the scenes. The condition filter means a Type 2 patient never sees Type 1 insulin pump troubleshooting guides, without the patient or the model needing to specify that constraint explicitly.
Tool Definitions
These consume context tokens regardless of whether they are used, and there's a genuine art to managing them. Inngest recommends removing any tool used less than 10% of the time because performance degrades as tool count grows. But Manus found that dynamically loading and removing tools breaks KV-cache (a 10x cost difference between cached and uncached tokens), so their solution is logits masking, where tools stay in context but get suppressed at the decoding level through a state machine.
I don't think there's a clean answer here yet. I'm currently leaning toward keeping tool counts low rather than worrying about cache-aware masking, mostly because my agents have 4-6 tools, not 40. If you're at Manus's scale with dozens of tools, the cache math probably dominates.
The broader principle from Manus's engineering blog applies regardless of tool count, which is to never mutate tokens already in the KV-cache prefix. Even changing JSON key ordering in a tool definition invalidates the cache from that point forward, and with agentic workloads running at roughly a 100:1 input-to-output token ratio, cache hits are existential for cost at scale. Both Anthropic and OpenAI now offer explicit cache control with up to 90% discounts on cached input tokens, but the gotchas will bite you. JSON key ordering instability in some languages (Swift, Go) can affect caches silently, toggling features like web search invalidates the system cache, and the cache follows a strict hierarchy (tools → system → messages) where changes at any level invalidate everything after it.
Structured Output
JSON schemas, type definitions, and output constraints are easy to overlook in a token budget because they feel like "free" structure, but the schema itself gets injected into the prompt behind the scenes. A moderately complex schemas, with nested objects with descriptions and enums, consume 300+ tokens, and that cost adds up pretty quickly at scale.
Write / Select / Compress / Isolate
- Write: move information out of the window into external storage
- Select: retrieve relevant information back via RAG or memory queries
- Compress: tiered approach (raw context → compact by stripping filler → summarize only when needed), compress proactively at 80-90% capacity, trim in atomic turn groups. Never compress instructions and data together
- Isolate: split work across separate LLM calls so each gets focused context
Most teams over-invest in writing and selecting; the real gains are in compression and isolation.
Every production context system I've seen uses some combination of four strategies, and LangChain's framework gives them clean names.
Writing
Similar to how humans writes down notes for future references, agents also benefit from getting information out of the context window and into external backend storage for later retrieval. Scratchpads let the agent write intermediate notes during a session (observations, partial results, plans) that persist via tool calls or state objects without occupying the window continuously. For example, the Manus team let their agents maintain a todo.md file during complex tasks, writing and re-reading their plan to counteract the "lost-in-the-middle" problem across ~50 average tool calls. It's charmingly simple for a state-of-the-art agent.
Selecting
The complement of writing is retrieving relevant information back when needed. This includes reading back scratchpad notes from earlier steps, querying stored memories using embeddings or keyword search, and full RAG pipelines over documents or code. If you have many tools, you can use RAG over tool descriptions to pick the right one (RAG-MCP paper saw selection accuracy increase from 13.6% to 43.1% compared to exposing all tools at once).
Selection quality depends heavily on query quality. My agent rewrites the user's message into a self-contained retrieval query before searching:
# "My numbers have been all over the place lately"
# -> "blood sugar management strategies Type 2 patient on metformin irregular post-meal readings"
async def rewrite(self, query, conversation_history, patient_profile):
recent_turns = conversation_history[-3:]
prompt = f"""Rewrite the search query to be self-contained.
Resolve pronouns, add implicit context from conversation.
Known: diagnosis={profile.diagnosis}, medications={profile.current_medications}
Rules:
- Keep it concise (under 30 words)
- Resolve pronouns ("it" -> the patient's condition)
- Strip emotional language, focus on the information need"""A completely reasonable query like "My numbers have been all over the place lately" has almost zero retrieval value because there's no condition or medication context. The rewriter infers "post-meal readings" from the last 3 turns, adds the patient's diagnosis and medication context, and produces a query that actually hits relevant documents.
Compressing
The goal is to reduce tokens while maintaining task performance, and production systems benefit from a tiered approach that matches the intensity of compression to how much pressure the window is actually under (imagine Claude Code running on a million-line codebase and websearching the entire Internet in parallel). You can think of it as three tiers:
- Raw context when below ~80% capacity. If the window has room, don't compress at all. Raw turns carry more signal than any summary.
- Compact first when approaching the budget. Strip low-signal content (greetings, filler acknowledgments, tool call boilerplate) while keeping messages structurally intact. Low/no LLM call needed.
- Summarize only when compaction isn't enough. Replace older turns with a generated summary, preserving the recent window verbatim.
The exact threshold is a judgment call that depends on your model and task, but I'd aim to start compacting somewhere in the 80-90% range rather than waiting until 95%. Let's call it the pre-rot threshold. By the time you're near 95%, attention quality has already started to degrade (this connects directly to the distraction failure mode in Section 4).
async def manage_context(self, session_id, current_turn, window_budget):
messages = await self._store.get_messages(session_id)
current_usage = estimate_tokens(messages)
# Tier 1: Raw context fits — do nothing
if current_usage < window_budget * 0.80:
return messages
# Tier 2: Compact — strip low-signal content, keep messages intact
compacted = self._compact(messages)
if estimate_tokens(compacted) < window_budget * 0.85:
return compacted
# Tier 3: Summarize — replace old turns with generated summary
cutoff = self._find_summary_boundary(compacted)
summary = await self._summarize(compacted[:cutoff])
return [summary_message(summary)] + compacted[cutoff:]The _compact step does straightforward stripping of "thanks!", "ok sounds good", empty assistant acknowledgments, and tool call metadata that the model doesn't need to see on future turns. The summarization tier only fires when compaction alone can't get below 85% capacity, which in practice means conversations beyond ~15 turns.
One interesting finding from the recurrent context compression research: compressing instructions and context simultaneously degrades responses. You need to compress the data but preserve the instructions separately, since they're treated differently at an attention level.
Trimming is the other half of compression. Production SDKs from both OpenAI and Anthropic trim in atomic turn groups, i.e. they group user messages, assistant messages, tool results that follow it, and remove them as a unit.
def trim_oldest_turn(messages):
"""Remove the oldest complete turn group atomically."""
if not messages:
return messages
i = 0
while i < len(messages):
if i > 0 and messages[i].role == "user":
break
i += 1
return messages[i:]The function walks forward from the start until it hits the next user message, then slices off everything before it. One complete turn (user message, assistant response, any tool calls and results in between) gets removed as an atomic unit. My agent calls this in a loop until the conversation fits within the character budget, which handles the same two problems as a message cap plus character budget but without the risk of orphaned tool results.
Isolating
Sometimes one context window isn't enough, and the right move is splitting information across separate processing units so each one gets a clean, focused window. Multi-agent systems give each sub-agent its own window focused on a specific subtask, returning a condensed summary (1,000-2,000 tokens) to the lead agent. HuggingFace's CodeAgent isolates token-heavy objects in sandbox environments, keeping only references in the main context. You can also separate LLM-exposed fields from auxiliary context storage in your state schema, because not everything the system knows needs to be in the window.
My agent isolates safety classification into separate LLM calls so the guardrail context never contaminates the main patient conversation:
# Each node runs in its own isolated LLM call with its own context
graph = StateGraph(CoachingState)
graph.add_node("input_gate", input_gate_node) # Safety classifier
graph.add_node("pro_react_agent", pro_agent) # Main agent (complex queries)
graph.add_node("flash_react_agent", flash_agent) # Main agent (simple messages)
graph.add_node("output_gate", output_gate_node) # Scope validator
graph.set_entry_point("input_gate")
graph.add_conditional_edges("input_gate", route_after_input_gate, {
END: END, # Blocked -> stop
"pro_react_agent": "pro_react_agent", # Complex -> Pro + thinking
"flash_react_agent": "flash_react_agent", # Simple -> Flash
})
graph.add_edge("pro_react_agent", "output_gate")
graph.add_edge("flash_react_agent", "output_gate")
graph.add_edge("output_gate", END)The input gate sees only the latest user message and a short classification prompt. The output gate sees only the agent's response and a scope-checking prompt. Neither gate's context (safety rules, classification examples) appears in the main agent's window, keeping the patient conversation clean and focused.
If you're building an agent and something feels off about the outputs, run through these four categories and ask which one you're neglecting. In my experience the answer is very often compression or isolation, less is more.
How Context Fails
Four context failure modes to watch for when an agent misbehaves: poisoning (errors compound), distraction (too much history), confusion (noise as signal), and clash (contradictory instructions). Different failures need different fixes.
When an agent misbehaves, my first question is always "what kind of context failure is this?" because the mitigations are completely different depending on the answer. The following four failure modes cover most of what goes wrong.
Four Context Failure Modes
Context Poisoning
This is the scariest one. A hallucination or error enters the context and gets repeatedly referenced, compounding mistakes over time. Once a wrong fact lands in the conversation history, the model treats it as ground truth and builds on it. Google DeepMind's Gemini 2.5 technical report showed just how bad this gets. A Pokemon-playing agent hallucinated the existence of an item called "TEA," wrote it into its goals scratchpad, and then spent hundreds of actions trying to find something that doesn't exist in the game. The agent also developed a "black-out strategy" (intentionally fainting all its Pokemon to teleport) rather than navigating normally. Once a hallucination enters a persistent scratchpad, the model treats it as ground truth and builds increasingly nonsensical plans on top of it. The fix is to validate information before writing to long-term memory, treating memory writes like database writes where you check constraints before committing.
Context Distraction
A more subtle failure. The context grows so long that the model over-focuses on accumulated history and neglects what it learned during training. Beyond ~100k tokens, I've noticed agents tend toward repeating actions from history rather than synthesizing novel plans. Aggressive trimming and summarization help, along with actively removing completed or irrelevant sections. I suspect most people's context windows are 2-3x larger than they need to be.
This is why the pre-rot threshold from Section 3 matters so much. If you wait until 95% capacity to compress, attention quality has already started to degrade.
Context Confusion
Superfluous information gets treated as signal because the model can't distinguish noise from relevant information when everything is dumped in together. Anthropic's guiding principle is the right one here: "find the smallest set of high-signal tokens that maximize the likelihood of your desired outcome."; every token should "earn" its place.
Context Clash
I find this the easiest to create accidentally. New information conflicts with existing information already in the prompt, and contradictory instructions produce unpredictable behavior. My own agent has one I caught during an audit for this post. The system prompt says "When READING information you already have in the patient context above, use it directly, do not re-fetch with get_patient_profile." But get_patient_profile is still available as a callable tool. The instruction and the tool list contradict each other. The agent sometimes calls the tool anyway, wasting a round-trip to fetch data that's already in the prompt. The fix is straightforward (remove the tool), but the clash was easy to miss because the instruction is in the <tools> section of the prompt and the tool definition is in Python code, and I never reviewed them side by side until I went looking for exactly this kind of problem.
There's a deeper mechanism behind context distraction that Chroma's research calls context rot. They attribute it to the $O(n^2)$ pairwise token relationships in self-attention, where at 100K+ tokens the model's attention budget is spread across billions of pair interactions, and critical information gets drowned out. The full story is more nuanced than that framing suggests. Factors like positional encoding degradation (especially RoPE-based encodings at positions beyond the training distribution), attention sink phenomena where early tokens absorb disproportionate weight, or training data skewing toward shorter contexts, all contribute.
The lost-in-the-middle finding (Liu et al., 2023) showed that performance degrades significantly when relevant information sits in the middle of long contexts versus the beginning or end. Liu et al. found a consistent U-shaped curve across models and settings, with accuracy dropping by 20%+ in some configurations. The exact magnitude varies by model, task, and number of documents, but the core result (middle positions perform worst) has been replicated across multiple studies and model families. (Frontier models have since made meaningful progress here, and the effect is less pronounced than when first measured.)
A Real Token Budget
Token budget from the diabetes coaching agent I built with LangGraph:
All of the above is easier to understand with a concrete example, so let me walk through the diabetes management coaching assistant I built as a ReAct agent with LangGraph. The system prompt ranges from ~2,000 to ~4,050 tokens depending on session maturity, assembled dynamically from several blocks.
Gated Dual-Agent Pipeline
| Component | Tokens | Type |
|---|---|---|
| Conversation state (turn count, phase, datetime) | 50-100 | Dynamic (every turn) |
| Identity block (personality, voice) | ~350 | Static |
| Boundaries (5 hard scope rules) | ~280 | Static |
| Patient context (profile, summary, goals) | 80-700 | Dynamic (per session) |
| Approach + tools + response guides | ~470 | Static |
| Few-shot examples (6) | ~550 | Static |
| RAG results (last 3, conditional) | 0-1,500 | Conditional |
| System prompt total | ~2,000-4,050 | Mixed |
| Conversation window (6 turns max) | 500-5,000 | Dynamic (rolling) |
Tool results (search_knowledge_base) | 0-10,000 | On-demand |
The conversation window holds 6 turns max, char-budgeted at 120,000 characters. Messages from turns already covered by the rolling summary are excluded.
Everything gets assembled in a single prepare_context hook that runs before every LLM call in the ReAct loop. The static sections form a stable prefix for KV-cache hits, and the volatile conversation state goes at the end:
async def prepare_context(state: CoachingState):
session_id = state.get("session_id", "default")
session_state = await session_store.get(session_id)
turn_count = session_state.turn_count
cache_key = (session_id, turn_count)
# Skip rebuild if nothing mutated since last call
has_mutation = _has_mutating_tool(state["messages"])
if cache_key in _prompt_cache and not has_mutation:
system_blocks = _prompt_cache[cache_key]
else:
summary = await session_store.get_latest_summary(session_id)
episodes = await session_store.get_recent_episodes(session_id, limit=5)
tool_results = await session_store.get_recent_tool_results(session_id, limit=3)
static_prompt = build_system_prompt(
profile=session_state.patient_profile,
active_strategies=session_state.active_strategies,
goals=session_state.goals, outcomes=session_state.outcomes,
session_summary=summary_text,
)
# Static prefix first (cacheable), volatile state appended last.
# cache_control breakpoint on the static block tells the API
# "everything up to here is reusable across turns."
state_block = build_conversation_state(turn_count, phase, recent_tool_names, ...)
system_blocks = [
{"type": "text", "text": static_prompt,
"cache_control": {"type": "ephemeral"}}, # <-- breakpoint
{"type": "text", "text": state_block}, # volatile, NOT cached
]
# Trim conversation: drop oldest complete turn groups atomically
conversation = [m for m in messages if not isinstance(m, SystemMessage)]
while estimate_chars(conversation) > remaining_budget and len(conversation) > 2:
conversation = trim_oldest_turn(conversation)
return {"system": system_blocks, "messages": conversation}This function is where all the context engineering actually happens. Load state, build the prompt from components, append the volatile state block at the end (so the static sections form a cacheable prefix), and trim the conversation using turn-group-aware removal. The cache_control breakpoint on the static block is key here as it tells the API where the reusable prefix ends, so everything before it gets reused across turns instead of re-processed.
Context Engineering Techniques Used
Two Catches from My Own Audit
- KV-cache violation: Volatile state prepended to prompt prefix, invalidating cache every turn (10x cost). Fix: move to end.
- Profile-in-prompt-and-tool clash:
get_patient_profileduplicates data already in system prompt; the tool's existence signals to the model that the profile might not be in context, making it less likely to trust data it already has.
When I audited this agent against the best practices I'd just finished researching, two problems jumped out that I wouldn't have caught without specifically looking.
The expensive one is a KV-cache violation. Look at the prepare_context code above. The volatile <conversation_state> block (which changes every turn with new turn count, new timestamp, new tool history) gets prepended to the start of the system prompt. KV-cache works by matching a prefix, so if the first N tokens are identical between calls, the provider can reuse the cached key-value pairs and charge you the cached rate. By putting volatile data at the very start, every single turn invalidates the entire cache. Manus reports this is a 10x cost difference ($0.30/MTok cached vs $3/MTok uncached on Claude Sonnet). To fix, just move the state block to the end of the prompt instead of the beginning, so the static sections (identity, boundaries, examples) form a stable prefix that caches across turns. The broader principle from Section 2 applies here too. You should treat the prompt prefix as append-only, sort sections by volatility, and let the stable parts form a cacheable prefix.
KV-Cache Prefix Ordering
The subtler one is a profile-in-prompt-and-tool clash. The patient profile is already injected into the <patient-context> section of the system prompt on every turn. But get_patient_profile also exists as a callable tool. The tool exists to let the agent "check what it knows," but the agent already knows; it's right there in the prompt. The instruction says "use the profile in <patient-context> directly," but the tool's mere availability creates an implicit counter-signal. Removing the tool entirely fixed the redundant fetches and, more importantly, made the agent more confident in referencing profile data from the prompt.
Measuring Context Quality
Track cache hit rate, cost per task, and task completion rate vs. context size. Run A/B tests on context strategies, not just prompts. Benchmarks exist (ContextBench, Letta Context-Bench) but your own eval suite matters more.
The one metric I track reliably is cache hit rate, because Anthropic hands it to you for free. Every API response includes cache_read_input_tokens and cache_creation_input_tokens, and the ratio tells you whether your prefix ordering is stable across turns. After fixing the KV-cache violation from Section 5, my cache hit rate went from ~0% to ~85% on turns 2+, which I could verify directly from the billing dashboard. If your cache hit rate is low, something in your prompt prefix is changing between calls, and the fix is almost always moving volatile content later in the prompt.
Beyond that, keep an eye on cost per conversation (total API spend divided by completed sessions) because it rolls up cache efficiency, context size, model routing, and retrieval volume into a single number. Letta's Context-Bench reinforces why this matters more than per-token price: Claude Sonnet 4.5 led their benchmark at 74.0% accuracy for $24.58, while GPT-5 reached 72.67% for $43.56, roughly 77% more expensive for slightly lower performance. Models with higher unit costs sometimes use far fewer tokens, so the aggregate figure is what counts.
On the benchmarking side, ContextBench is worth knowing about. It tests whether coding agents can retrieve the right context from 66 real repositories across 8 languages, and the headline numbers are not great, as even SOTA models achieve block-level F1 below 0.45 and line-level F1 below 0.35. Higher recall was consistently favored over precision, suggesting it's better to include a few irrelevant chunks than to miss a critical one. Sophisticated scaffolding didn't necessarily lead to better retrieval either, which complicates the "just add more RAG infrastructure" instinct.
Lesson
Context engineering is mostly about removal, not addition. Every improvement involved taking something out or moving it around. Context strategy isn't portable across providers; test on every model you support. Input tokens can outnumber output tokens by 100:1 in heavy agentic workloads, so context-side optimization has economic leverage, and that makes this a skill worth knowing.
If I had to distill this post into one actionable idea, it's that context engineering is mostly about removal, not addition. The instinct is always to add more information, more tools, more history, more instructions. But every improvement I've made to my agent involved taking something out or moving it around, not putting more in. Remove the redundant tool. Move the volatile state block to the end of the prompt. Compress proactively at 80-90% capacity instead of reactively at 95%. Trim in atomic turn groups instead of shaving individual messages.
One caveat worth keeping in mind as you apply any of this. Context strategy isn't portable across providers. Different models have different attention patterns, different context window behaviors, and different sensitivities to prompt structure. What works for Claude might fail on GPT might fail on Gemini. I've been burned by this enough times that I now test prompts on every model I plan to support, rather than assuming my architecture generalizes.
Why I Think This Skill Has Legs
We've spent decades aggregating essentially the entire body of human knowledge work into model weights you can query for cents. A question that once took a junior analyst half a day now costs a few pennies in API calls. But cheap isn't free, and you're still buying tokens. In production agent systems, input tokens outnumber output tokens by roughly 100:1, which means the context side of the bill dominates. I showed earlier that a single ordering mistake in my prompt produced a 10x cost difference, and if you scale that kind of waste to millions of conversations, even a 1% optimization on the input side ends up mattering more than a 50% optimization on the output side, simply because there's so much more of it.
Wherever there's a cost curve with room to optimize, there tends to be demand for people who can optimize it. That was true for database query planning, for network packet routing, for GPU kernel tuning, and I think it'll be true for context assembly. Models will keep getting cheaper per token, but usage is growing faster than prices are dropping, and the gap between "the model can do this task" and "the model does this task reliably at scale" is exactly where context engineering lives.
If you spot errors or have war stories from your own context engineering work, I'd love to hear about it on X or LinkedIn.
References
- Karpathy, A. "Context Engineering." X/Twitter, June 2025.
- Rajasekaran, P. et al. "Effective Context Engineering for AI Agents." Anthropic Engineering, September 2025.
- Martin, L. "Context Engineering for Agents." LangChain Blog, July 2025.
- Ji, Y. "Context Engineering for AI Agents: Lessons from Building Manus." Manus Blog, July 2025.
- Inngest. "Five Critical Lessons for Context Engineering." inngest.com, 2025.
- Hsieh, C.-P. et al. "RULER: What's the Real Context Size of Your Long-Context Language Models?" arXiv:2404.06654, 2024. Published at COLM 2024.
- Liu, N.F. et al. "Lost in the Middle: How Language Models Use Long Contexts." arXiv:2307.03172, 2023. Published in TACL, 2024.
- Wu, D. et al. "LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory." arXiv:2410.10813, 2024. Published at ICLR 2025.
- Anthropic. "How We Built Our Multi-Agent Research System." Anthropic Engineering, November 2025.
- OpenAI. "Agents SDK." GitHub, 2025.
- Huang, Y. et al. "Recurrent Context Compression: Efficiently Expanding the Context Window of LLM." arXiv:2406.06110, 2024.
- Writer.com. "RAG-MCP: Mitigating Prompt Bloat in Tool-Augmented LLMs." arXiv:2505.03275, 2025.
- Letta. "Context-Bench: Benchmarking Long-Horizon Agent Memory." letta.com, October 2025.
- Fournier, C. et al. "ContextBench: A Benchmark for Context Retrieval in Coding Agents." arXiv:2602.05892, February 2026.
- Google DeepMind. "Gemini 2.5: Our Most Intelligent AI Model." Technical Report, 2025.
- Google. "Agent Development Kit: Build, Evaluate, and Deploy Agents." google.github.io/adk-docs, 2025.
- HuggingFace. "Code Agents." HuggingFace Docs, 2025.
- Anthropic. "Prompt Caching." Anthropic Docs, 2024.
- OpenAI. "Prompt Caching." OpenAI Docs, 2024.
- Hong, K., Troynikov, A., Huber, J. "Context Rot: How Increasing Input Tokens Impacts LLM Performance." Chroma Research, July 2025.